WSL2 is incredibly convenient. However, for my use case, where I’m running a Hyper-V host with separate VMs, one key struggle was GPU acceleration. What I ended up doing in the past was just pass thru, but if you have multiple VMs, GPU partitioning (GPU-P) and GPU paravirtualization (GPU-PV) allows you to partition and share your GPU across several VMs. Pretty cool feature if you have things that can benefit (e.g. Jellyfin, Immich, etc.).
The setup above is well documented on Windows guests and fairly easy to implement, but getting a fully functional Hyper-V GPU-PV Docker setup working on a modern Linux guest is much harder. First, you have to map the GPU. Next, you must compile Microsoft’s kernel module. Finally, you manually bridge the Windows drivers.
Here is a guide I put together for building a strictly isolated Ubuntu VM (tested on 24.04 and 26.04). It should work on other Linux distros too. Hope it can help if you are interested in a similar setup!
VM & GPU Partitioning (Windows Host)
To begin with, create a Generation 2 Virtual Machine in Hyper-V Manager using your Ubuntu Server ISO. Specifically, configure these settings before booting:
- Memory: Disable “Dynamic Memory”.
- Security: Disable “Secure Boot” (Custom kernel drivers will fail otherwise).
- Checkpoints: Disable “Automatic Checkpoints” (Breaks memory mapping).
Meanwhile, keep the VM turned off. Open PowerShell as Administrator to assign a partition of your host GPU:
$vm = "YourVMName"
# 1. Power off the guest before changing adapters
Stop-VM -VMName $vm -Force
# 2. Remove ANY existing GPU-PV adapters to ensure a clean slate
Get-VMGpuPartitionAdapter -VMName $vm | Remove-VMGpuPartitionAdapter
# 3. Re-apply the MMIO settings for a 24GB+ GPU
Set-VM -VMName $vm -GuestControlledCacheTypes $true -LowMemoryMappedIoSpace 1GB -HighMemoryMappedIoSpace 32GB
# 4. Add adapter
Add-VMGpuPartitionAdapter -VMName $vm
# 5. Verify the final state (Should only list one adapter)
Get-VMGpuPartitionAdapter -VMName $vm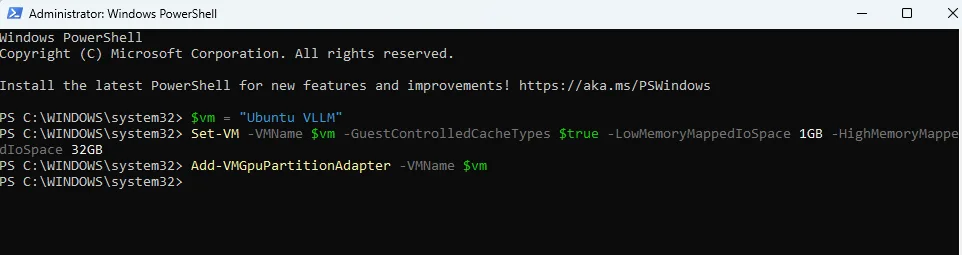
Afterward, boot the VM and install Ubuntu normally.
Compiling the Kernel Module (Ubuntu Guest)
Modern Ubuntu runs newer kernels (like 6.8+). Previously, compiling Microsoft’s DirectX Linux kernel (dxgkrnl) was a nightmare of manual C-code patching. By cloning a branch of the WSL kernel that aligns with our system’s era, we can bypass most API conflicts.
However, because we are building this driver “out-of-tree” (separate from the rest of Microsoft’s massive kernel repository), the DKMS compiler will fail silently unless we copy a few missing header files, apply one function patch, and properly configure the Kbuild variables.
First, SSH into your Ubuntu VM, install the build tools, and clone the 6.6.y branch for Ubuntu 24.04, or the 6.18.y branch for Ubuntu 26.04:
# Install build tools and current kernel headers
sudo apt update && sudo apt install -y git dkms build-essential linux-headers-$(uname -r)
# Clone the 6.18 branch from Microsoft's WSL kernel
git clone -b linux-msft-wsl-6.18.y --depth=1 https://github.com/microsoft/WSL2-Linux-Kernel
cd WSL2-Linux-Kernel
VERSION=$(git rev-parse --short HEAD)Next, copy the driver and the missing headers into your system’s source directory. Furthermore, we must patch a specific C-function that changed in kernel 6.8+, and update the Makefile to use the correct $(src) variable:
# 1. Copy the main driver folder
sudo cp -r drivers/hv/dxgkrnl /usr/src/dxgkrnl-$VERSION
# 2. Copy the missing required headers
sudo mkdir -p /usr/src/dxgkrnl-$VERSION/inc/{uapi/misc,linux}
sudo cp include/uapi/misc/d3dkmthk.h /usr/src/dxgkrnl-$VERSION/inc/uapi/misc/d3dkmthk.h
sudo cp include/linux/hyperv.h /usr/src/dxgkrnl-$VERSION/inc/linux/hyperv_dxgkrnl.h
# 3. Point the C-code to our locally copied header
sudo sed -i 's#linux/hyperv.h#linux/hyperv_dxgkrnl.h#' /usr/src/dxgkrnl-$VERSION/dxgmodule.c
# 4. FIX FOR MODERN UBUNTU (Kernel 6.8+ API change)
sudo sed -i 's/eventfd_signal(event->cpu_event, 1)/eventfd_signal(event->cpu_event)/' /usr/src/dxgkrnl-$VERSION/dxgmodule.c
# 5. Patch the Makefile to force it to build out-of-tree correctly
sudo sed -i 's/\$(CONFIG_DXGKRNL)/m/' /usr/src/dxgkrnl-$VERSION/Makefile
sudo bash -c "echo 'ccflags-y += -I\$(src)/inc' >> /usr/src/dxgkrnl-$VERSION/Makefile"Finally, build and install the module directly via DKMS. Consequently, the module will survive minor kernel updates without needing to be manually recompiled every time your VM updates:
# Create the DKMS config
sudo sh -c "cat > /usr/src/dxgkrnl-$VERSION/dkms.conf <<EOF
PACKAGE_NAME=\"dxgkrnl\"
PACKAGE_VERSION=\"$VERSION\"
BUILT_MODULE_NAME=\"dxgkrnl\"
DEST_MODULE_LOCATION=\"/kernel/drivers/hv/dxgkrnl/\"
AUTOINSTALL=\"yes\"
EOF"
# Add, build, and install
sudo dkms add dxgkrnl/$VERSION
sudo dkms build dxgkrnl/$VERSION
sudo dkms install dxgkrnl/$VERSION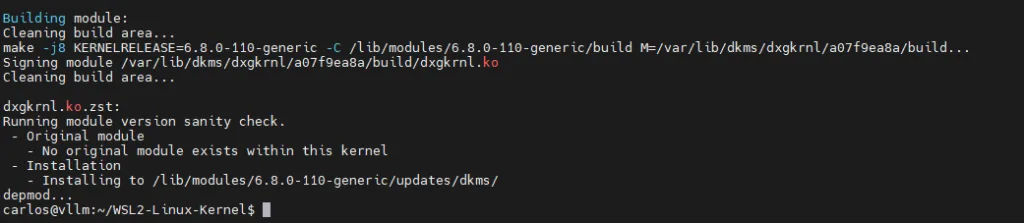
A successful DKMS build confirms the translation module is permanently active in the Ubuntu kernel. (24.04)
Sourcing and Bridging Drivers for Hyper-V GPU-PV Docker
Reboot the VM. The VM kernel can now talk to Hyper-V. However, it lacks the actual hardware drivers and translation binaries. Therefore, you need to pull them directly from your Windows host system to complete your Hyper-V GPU-PV Docker setup.
This is where most setups fail. Microsoft’s driver stack requires a very specific, three-tier separation of files. If you flatten these folders, PyTorch will instantly crash with Error 500 (Symbol not found) or Error 100 (No Devices) because the translation loaders will fail to initialize.
First, open PowerShell as Administrator on Windows. The following script will download the core WSL engines, automatically locate your newest active NVIDIA driver folder, and securely transfer all three architecture components to your Ubuntu VM:
# Run from Windows PowerShell as Administrator
# --- Configuration Variables ---
$vmUser = "user" # Replace with your actual VM username
$vmIp = "192.168.0.10" # Replace with your actual VM IP address
# -------------------------------
# 1. Download the translation binaries (no distro needed)
wsl --install --no-distribution
# 2. Automatically find your NEWEST NVIDIA driver folder
$nvFolder = Get-ChildItem "C:\Windows\System32\DriverStore\FileRepository\nv_dispi.inf_amd64_*" | Sort-Object LastWriteTime -Descending | Select-Object -First 1 -ExpandProperty Name
# Safety check to ensure the folder was actually found
if (-not $nvFolder) {
Write-Error "NVIDIA driver folder not found. Please ensure the drivers are installed on the host."
exit
}
# 3. Transfer the THREE required driver tiers to your Ubuntu home directory
scp -r "C:\Windows\System32\lxss\lib" "${vmUser}@${vmIp}:~/lxss_lib"
scp -r "C:\Program Files\WSL\lib" "${vmUser}@${vmIp}:~/wsl_lib"
scp -r "C:\Windows\System32\DriverStore\FileRepository\$nvFolder" "${vmUser}@${vmIp}:~/$nvFolder"Next, go back into your Ubuntu VM. We are going to construct the exact folder hierarchy that the dxgkrnl module demands: Stubs and Translation Cores go in the lib folder, while the massive Hardware Backend must remain isolated inside its specific INF subfolder.
# Extract the dynamic folder name we copied from Windows
NV_FOLDER=$(ls -d ~/nv_dispi* | xargs -n 1 basename)
# 1. Clean the slate and build the exact structural scaffolding
sudo rm -rf /usr/lib/wsl
sudo mkdir -p /usr/lib/wsl/lib
sudo mkdir -p /usr/lib/wsl/drivers/$NV_FOLDER
# 2. Populate the WSL Stubs (The tiny 179KB redirect files)
sudo cp -a ~/lxss_lib/* /usr/lib/wsl/lib/
# 3. Populate the Microsoft Translation Core
sudo cp -a ~/wsl_lib/* /usr/lib/wsl/lib/
# Fix Microsoft's case-sensitivity bug
sudo cp /usr/lib/wsl/lib/libd3d12core.so /usr/lib/wsl/lib/libD3D12Core.so
sudo cp /usr/lib/wsl/lib/libdxcore.so /usr/lib/wsl/lib/libDXCore.so
# 4. Populate the Heavy NVIDIA Backend (Must go INSIDE the INF folder!)
sudo cp -a ~/$NV_FOLDER/* /usr/lib/wsl/drivers/$NV_FOLDER/
# 5. Expose nvidia-smi for convenience
sudo cp ~/$NV_FOLDER/nvidia-smi /usr/lib/wsl/drivers/
sudo ln -sf /usr/lib/wsl/drivers/nvidia-smi /usr/bin/nvidia-smi
# 6. Lock down folder permissions and unblock device access
sudo chmod -R 755 /usr/lib/wsl
sudo chmod 666 /dev/dxg
# 7. Update the library cache so the kernel sees the layout
echo -e "/usr/lib/wsl/lib\n/usr/lib/wsl/drivers" | sudo tee /etc/ld.so.conf.d/ld.wsl.conf
sudo ldconfig
# 8. Clean up staging folders
rm -rf ~/lxss_lib ~/wsl_lib ~/$NV_FOLDER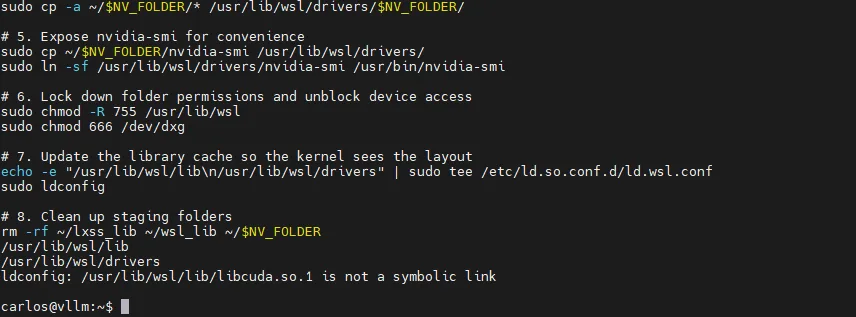
Moreover, you can now safely uninstall the WSL engine from your Windows host to keep your machine perfectly clean. The copied translation binaries will live happily inside your VM forever.
# Optional: Clean up Windows host
wsl --uninstallVerifying the Bridge (Diagnostic Script)
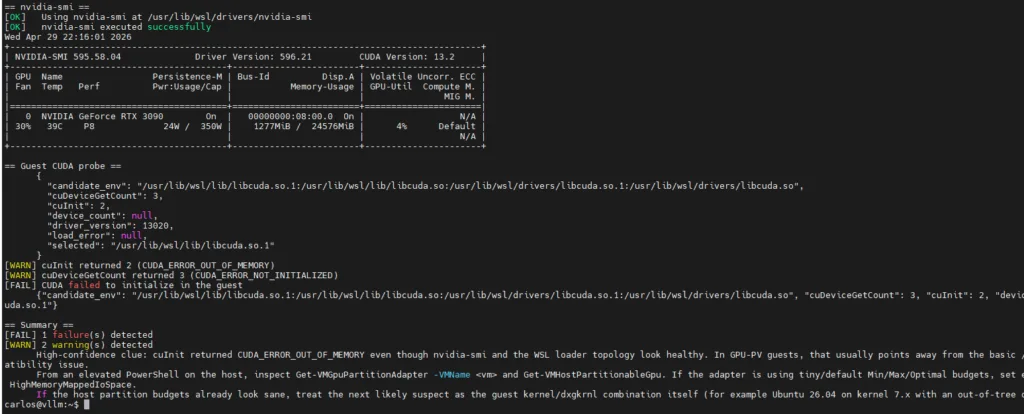
Before launching Docker, it is highly recommended to run a diagnostic to ensure the translation loaders are correctly interpreting your files. If the architecture is built correctly, both nvidia-smi and the CUDA compute initialization process will return a perfect success.
Create a python file named diag.py and paste the following auditing script:
#!/usr/bin/env python3
"""Read-only diagnostics for Hyper-V GPU-PV / dxgkrnl / WSL-style CUDA stacks.
This script is aimed at Linux guests that emulate WSL GPU support by exposing
`/dev/dxg` and copying Windows-provided libraries into `/usr/lib/wsl`.
It helps answer two questions:
1. Does CUDA initialize in the guest itself?
2. If guest CUDA works, does it also work inside a container?
"""
from __future__ import annotations
import argparse
import json
import os
from pathlib import Path
import shutil
import subprocess
import sys
import textwrap
from typing import Iterable
DEFAULT_IMAGE = "python:3.11-slim"
CUDA_ERROR_NAMES = {
0: "CUDA_SUCCESS",
1: "CUDA_ERROR_INVALID_VALUE",
2: "CUDA_ERROR_OUT_OF_MEMORY",
3: "CUDA_ERROR_NOT_INITIALIZED",
100: "CUDA_ERROR_NO_DEVICE",
500: "CUDA_ERROR_NOT_FOUND",
}
EXPECTED_DRIVER_LOADERS = [
"libcuda_loader.so",
"libnvidia-ml_loader.so",
"libnvdxgdmal.so.1",
"libnvwgf2umx.so",
]
KEY_LIBS = [
"libcuda.so",
"libcuda.so.1",
"libnvidia-ml.so.1",
"libdxcore.so",
"libd3d12.so",
"libd3d12core.so",
]
OPTIONAL_LIBS = ["libD3D12Core.so"]
SMI_CANDIDATES = [
"/usr/lib/wsl/drivers/nvidia-smi",
"/usr/lib/wsl/lib/nvidia-smi",
"nvidia-smi",
]
CUDA_PROBE_CODE = r'''
import ctypes
import json
import os
import sys
from pathlib import Path
result = {
"candidate_env": os.environ.get("GPUPV_CUDA_PATHS", ""),
"selected": None,
"load_error": None,
"driver_version": None,
"cuInit": None,
"cuDeviceGetCount": None,
"device_count": None,
}
candidates = [p for p in os.environ.get("GPUPV_CUDA_PATHS", "").split(os.pathsep) if p]
for candidate in candidates:
if Path(candidate).exists():
result["selected"] = candidate
break
if result["selected"] is None:
result["selected"] = "libcuda.so.1"
try:
mode = getattr(ctypes, "RTLD_GLOBAL", 0)
cuda = ctypes.CDLL(result["selected"], mode=mode)
except OSError as exc:
result["load_error"] = str(exc)
print(json.dumps(result, sort_keys=True))
raise SystemExit(2)
cuInit = cuda.cuInit
cuInit.argtypes = [ctypes.c_uint]
cuInit.restype = ctypes.c_int
cuDriverGetVersion = cuda.cuDriverGetVersion
cuDriverGetVersion.argtypes = [ctypes.POINTER(ctypes.c_int)]
cuDriverGetVersion.restype = ctypes.c_int
cuDeviceGetCount = cuda.cuDeviceGetCount
cuDeviceGetCount.argtypes = [ctypes.POINTER(ctypes.c_int)]
cuDeviceGetCount.restype = ctypes.c_int
version = ctypes.c_int(-1)
ret_version = cuDriverGetVersion(ctypes.byref(version))
if ret_version == 0:
result["driver_version"] = version.value
else:
result["driver_version"] = f"error:{ret_version}"
ret_init = cuInit(0)
result["cuInit"] = ret_init
count = ctypes.c_int(-1)
ret_count = cuDeviceGetCount(ctypes.byref(count))
result["cuDeviceGetCount"] = ret_count
if ret_count == 0:
result["device_count"] = count.value
print(json.dumps(result, sort_keys=True))
raise SystemExit(0 if ret_init == 0 else 3)
'''
class DiagnosticRunner:
def __init__(self, docker: bool, image: str) -> None:
self.docker = docker
self.image = image
self.failures: list[str] = []
self.warnings: list[str] = []
self.status: dict[str, object] = {}
self.base_env = os.environ.copy()
self.base_env["LD_LIBRARY_PATH"] = self._merged_ld_library_path()
@staticmethod
def _merged_ld_library_path() -> str:
prefix = ["/usr/lib/wsl/lib", "/usr/lib/wsl/drivers"]
existing = os.environ.get("LD_LIBRARY_PATH", "")
return os.pathsep.join(prefix + ([existing] if existing else []))
def section(self, title: str) -> None:
print(f"\n== {title} ==")
def ok(self, message: str) -> None:
print(f"[OK] {message}")
def warn(self, message: str) -> None:
self.warnings.append(message)
print(f"[WARN] {message}")
def fail(self, message: str) -> None:
self.failures.append(message)
print(f"[FAIL] {message}")
@staticmethod
def cuda_error_name(code: object) -> str | None:
if isinstance(code, int):
return CUDA_ERROR_NAMES.get(code)
return None
def run_command(
self,
command: list[str],
*,
timeout: int = 30,
env: dict[str, str] | None = None,
) -> subprocess.CompletedProcess[str]:
effective_env = self.base_env.copy()
if env:
effective_env.update(env)
return subprocess.run(
command,
text=True,
capture_output=True,
timeout=timeout,
env=effective_env,
check=False,
)
@staticmethod
def first_existing(paths: Iterable[str]) -> str | None:
for item in paths:
resolved = shutil.which(item) if os.path.sep not in item else item
if resolved and Path(resolved).exists():
return resolved
return None
@staticmethod
def collect_under_wsl(name: str) -> list[str]:
root = Path("/usr/lib/wsl")
if not root.exists():
return []
return sorted(str(path) for path in root.rglob(name))
@staticmethod
def describe_path(path: Path) -> str:
try:
stat = path.lstat()
except OSError as exc:
return f"{path} (unreadable: {exc})"
kind = "symlink" if path.is_symlink() else "file"
size = stat.st_size
suffix = ""
if path.is_symlink():
try:
suffix = f" -> {os.readlink(path)}"
except OSError:
suffix = " -> <unreadable target>"
return f"{path} ({kind}, {size} bytes{suffix})"
def check_platform(self) -> None:
self.section("Platform")
self.ok(f"Python executable: {sys.executable}")
self.ok(f"LD_LIBRARY_PATH: {self.base_env['LD_LIBRARY_PATH']}")
uname = shutil.which("uname")
if uname:
result = self.run_command([uname, "-a"])
if result.returncode == 0 and result.stdout.strip():
print(result.stdout.strip())
os_release = Path("/etc/os-release")
if os_release.exists():
pretty = None
for line in os_release.read_text(encoding="utf-8", errors="ignore").splitlines():
if line.startswith("PRETTY_NAME="):
pretty = line.split("=", 1)[1].strip().strip('"')
break
if pretty:
self.ok(f"OS: {pretty}")
def check_dxg(self) -> None:
self.section("dxg device and kernel")
if Path("/dev/dxg").exists():
self.ok("/dev/dxg exists")
self.status["dxg_device"] = True
else:
self.fail("/dev/dxg is missing")
self.status["dxg_device"] = False
lsmod = shutil.which("lsmod")
if lsmod:
result = self.run_command([lsmod])
if result.returncode == 0:
if any(line.startswith("dxgkrnl ") for line in result.stdout.splitlines()):
self.ok("dxgkrnl module is loaded")
self.status["dxgkrnl_loaded"] = True
else:
self.warn("dxgkrnl module not visible in lsmod output")
self.status["dxgkrnl_loaded"] = False
else:
self.warn("lsmod is unavailable; skipping dxgkrnl module check")
lspci = shutil.which("lspci")
if lspci:
result = self.run_command([lspci, "-nnk"], timeout=45)
if result.returncode == 0:
interesting = [
line for line in result.stdout.splitlines()
if "Microsoft Corporation" in line or "Kernel driver in use: dxgkrnl" in line
]
if interesting:
for line in interesting[:8]:
print(f" {line}")
else:
self.warn("lspci did not show obvious Microsoft/dxgkrnl entries")
else:
self.warn("lspci is unavailable; skipping PCI probe output")
def check_wsl_payload(self) -> None:
self.section("WSL-style payload")
wsl_root = Path("/usr/lib/wsl")
if not wsl_root.exists():
self.fail("/usr/lib/wsl is missing")
return
self.ok("/usr/lib/wsl exists")
for subdir in ("lib", "drivers"):
target = wsl_root / subdir
if target.exists():
self.ok(f"{target} exists")
else:
self.fail(f"{target} is missing")
for lib_name in KEY_LIBS:
matches = self.collect_under_wsl(lib_name)
if matches:
self.ok(f"Found {lib_name} under /usr/lib/wsl")
for match in matches[:3]:
print(f" {match}")
else:
self.fail(f"Missing {lib_name} under /usr/lib/wsl")
for lib_name in OPTIONAL_LIBS:
matches = self.collect_under_wsl(lib_name)
if matches:
self.ok(f"Found optional compatibility alias {lib_name}")
else:
lower = self.collect_under_wsl("libd3d12core.so")
if lower:
self.warn(
"libD3D12Core.so is missing while libd3d12core.so exists; "
"the guide's case-sensitivity symlink workaround may be missing"
)
else:
self.warn(f"Optional compatibility alias {lib_name} not found")
libcuda_in_wsl_lib = any((wsl_root / "lib" / name).exists() for name in ("libcuda.so", "libcuda.so.1"))
self.status["libcuda_in_wsl_lib"] = libcuda_in_wsl_lib
if libcuda_in_wsl_lib:
self.ok("Found libcuda.so* in /usr/lib/wsl/lib")
else:
self.warn(
"No libcuda.so* found under /usr/lib/wsl/lib. In official WSL, the CUDA shim normally lives there; "
"falling back to /usr/lib/wsl/drivers/libcuda.so can lead to CUDA_ERROR_NO_DEVICE."
)
self.check_loader_topology(wsl_root)
ldconfig = shutil.which("ldconfig")
if not ldconfig:
self.warn("ldconfig is unavailable; skipping loader-path inspection")
return
result = self.run_command([ldconfig, "-p"])
if result.returncode != 0:
self.warn("ldconfig -p failed; skipping loader-path inspection")
return
lines = result.stdout.splitlines()
for lib_name in ("libcuda.so.1", "libnvidia-ml.so.1", "libdxcore.so", "libd3d12.so"):
matches = [line.strip() for line in lines if lib_name in line]
if not matches:
self.warn(f"ldconfig does not currently expose {lib_name}")
continue
preferred = [line for line in matches if "/usr/lib/wsl/" in line]
if preferred:
self.ok(f"ldconfig exposes {lib_name} from /usr/lib/wsl")
else:
self.warn(f"ldconfig exposes {lib_name}, but not from /usr/lib/wsl")
shadow = [line for line in matches if "/usr/lib/wsl/" not in line]
for line in shadow[:3]:
self.warn(f"Potential shadowing entry for {lib_name}: {line}")
def check_loader_topology(self, wsl_root: Path) -> None:
lib_dir = wsl_root / "lib"
drivers_dir = wsl_root / "drivers"
libcuda_paths = [lib_dir / "libcuda.so", lib_dir / "libcuda.so.1", lib_dir / "libcuda.so.1.1"]
existing_libcuda = [path for path in libcuda_paths if path.exists() or path.is_symlink()]
if existing_libcuda:
self.ok("libcuda layout in /usr/lib/wsl/lib:")
for path in existing_libcuda:
print(f" {self.describe_path(path)}")
shim_candidate = lib_dir / "libcuda.so.1"
if shim_candidate.exists() or shim_candidate.is_symlink():
if shim_candidate.is_symlink():
target_name = os.readlink(shim_candidate)
self.status["libcuda_symlink_target"] = target_name
if target_name == "libcuda_loader.so":
loader_path = lib_dir / target_name
if loader_path.exists():
self.ok("libcuda.so.1 points to libcuda_loader.so and the target exists")
else:
self.fail("libcuda.so.1 points to libcuda_loader.so, but libcuda_loader.so is missing from /usr/lib/wsl/lib")
else:
self.warn(f"libcuda.so.1 symlink target is {target_name!r}; expected a regular WSL shim or libcuda_loader.so")
else:
size = shim_candidate.stat().st_size
self.status["libcuda_shim_size"] = size
if size < 1024 * 1024:
self.ok("libcuda.so.1 looks like a small WSL shim/stub")
else:
self.warn(
f"libcuda.so.1 in /usr/lib/wsl/lib is {size} bytes; that looks like a full driver binary, not the small WSL shim."
)
nested_driver_dirs = sorted(path for path in drivers_dir.iterdir() if path.is_dir()) if drivers_dir.exists() else []
if nested_driver_dirs:
self.ok("Nested driver directories under /usr/lib/wsl/drivers:")
for path in nested_driver_dirs[:5]:
print(f" {path}")
else:
self.warn(
"No nested driver directory exists under /usr/lib/wsl/drivers. WSL GPU stacks normally rely on an INF-style subdirectory containing loader libraries."
)
found_any_loader = False
missing_loader_names: list[str] = []
for loader_name in EXPECTED_DRIVER_LOADERS:
matches = self.collect_under_wsl(loader_name)
if matches:
found_any_loader = True
self.ok(f"Found {loader_name} under /usr/lib/wsl")
for match in matches[:3]:
print(f" {match}")
else:
missing_loader_names.append(loader_name)
self.warn(f"Missing {loader_name} under /usr/lib/wsl")
self.status["has_driver_loader_topology"] = found_any_loader and not missing_loader_names
if missing_loader_names:
self.warn(
"Missing one or more key driver-loader files. If nvidia-smi works but CUDA still returns NO_DEVICE/NOT_FOUND, this is a likely root cause."
)
def check_nvidia_smi(self) -> None:
self.section("nvidia-smi")
smi = self.first_existing(SMI_CANDIDATES)
if not smi:
self.fail("Could not locate nvidia-smi in /usr/lib/wsl or PATH")
self.status["guest_smi"] = False
return
self.ok(f"Using nvidia-smi at {smi}")
result = self.run_command([smi], timeout=45)
if result.returncode == 0 and "NVIDIA-SMI" in result.stdout:
self.ok("nvidia-smi executed successfully")
self.status["guest_smi"] = True
smi_cuda_err = "CUDA Version: ERR!" in result.stdout
self.status["smi_cuda_version_err"] = smi_cuda_err
if smi_cuda_err:
self.warn(
"nvidia-smi reports 'CUDA Version: ERR!'. That usually means the management path works, "
"but the CUDA compute stack is incomplete or incompatible."
)
preview = "\n".join(result.stdout.splitlines()[:12])
if preview:
print(preview)
else:
self.fail("nvidia-smi failed")
self.status["guest_smi"] = False
combined = (result.stdout + "\n" + result.stderr).strip()
if combined:
print(textwrap.indent(combined[:3000], " "))
def run_cuda_probe(self, command: list[str], *, timeout: int = 60) -> tuple[bool, dict[str, object] | None, str]:
candidates = [
"/usr/lib/wsl/lib/libcuda.so.1",
"/usr/lib/wsl/lib/libcuda.so",
"/usr/lib/wsl/drivers/libcuda.so.1",
"/usr/lib/wsl/drivers/libcuda.so",
]
env = {
"GPUPV_CUDA_PATHS": os.pathsep.join(candidates),
}
result = self.run_command(command, timeout=timeout, env=env)
payload_text = (result.stdout or "").strip().splitlines()
payload = None
if payload_text:
last_line = payload_text[-1]
try:
payload = json.loads(last_line)
except json.JSONDecodeError:
payload = None
success = result.returncode == 0 and bool(payload) and payload.get("cuInit") == 0
combined_output = ((result.stdout or "") + ("\n" if result.stderr else "") + (result.stderr or "")).strip()
return success, payload, combined_output
def check_guest_cuda(self) -> None:
self.section("Guest CUDA probe")
success, payload, output = self.run_cuda_probe([sys.executable, "-c", CUDA_PROBE_CODE])
self.status["guest_cuda"] = success
if payload:
self.status["guest_cuInit"] = payload.get("cuInit")
self.status["guest_cuDeviceGetCount"] = payload.get("cuDeviceGetCount")
print(textwrap.indent(json.dumps(payload, indent=2, sort_keys=True), " "))
cu_init_name = self.cuda_error_name(payload.get("cuInit"))
if payload.get("cuInit") == 0:
if cu_init_name:
self.ok(f"cuInit returned 0 ({cu_init_name})")
else:
self.ok("cuInit returned 0")
else:
if cu_init_name:
self.warn(f"cuInit returned {payload.get('cuInit')} ({cu_init_name})")
else:
self.warn(f"cuInit returned {payload.get('cuInit')}")
cu_count_name = self.cuda_error_name(payload.get("cuDeviceGetCount"))
if payload.get("cuDeviceGetCount") != 0:
if cu_count_name:
self.warn(
f"cuDeviceGetCount returned {payload.get('cuDeviceGetCount')} ({cu_count_name})"
)
else:
self.warn(f"cuDeviceGetCount returned {payload.get('cuDeviceGetCount')}")
selected = payload.get("selected")
if (
isinstance(selected, str)
and selected.startswith("/usr/lib/wsl/drivers/")
and self.status.get("libcuda_in_wsl_lib") is False
):
self.warn(
"The probe loaded libcuda from /usr/lib/wsl/drivers because no libcuda.so* was found in /usr/lib/wsl/lib. "
"That is suspicious for a WSL-style setup and is a strong candidate root cause."
)
if success:
self.ok("CUDA initialized successfully in the guest")
else:
self.fail("CUDA failed to initialize in the guest")
if output:
print(textwrap.indent(output[:3000], " "))
def check_container_cuda(self) -> None:
if not self.docker:
return
self.section("Container CUDA probe")
docker = shutil.which("docker")
if not docker:
self.fail("docker is not installed or not on PATH")
self.status["container_cuda"] = False
return
if not Path("/dev/dxg").exists():
self.fail("Skipping container probe because /dev/dxg is missing")
self.status["container_cuda"] = False
return
command = [
docker,
"run",
"--rm",
"--device",
"/dev/dxg:/dev/dxg",
"-v",
"/usr/lib/wsl:/usr/lib/wsl:ro",
"-e",
"LD_LIBRARY_PATH=/usr/lib/wsl/lib:/usr/lib/wsl/drivers",
"-e",
"GPUPV_CUDA_PATHS=/usr/lib/wsl/lib/libcuda.so.1:/usr/lib/wsl/lib/libcuda.so:/usr/lib/wsl/drivers/libcuda.so.1:/usr/lib/wsl/drivers/libcuda.so",
self.image,
"python",
"-c",
CUDA_PROBE_CODE,
]
success, payload, output = self.run_cuda_probe(command, timeout=300)
self.status["container_cuda"] = success
if payload:
print(textwrap.indent(json.dumps(payload, indent=2, sort_keys=True), " "))
if success:
self.ok(f"CUDA initialized successfully inside container image {self.image}")
else:
self.fail(f"CUDA failed to initialize inside container image {self.image}")
if output:
print(textwrap.indent(output[:4000], " "))
def print_summary(self) -> None:
self.section("Summary")
if not self.failures:
self.ok("No hard failures detected")
else:
self.fail(f"{len(self.failures)} failure(s) detected")
if self.warnings:
self.warn(f"{len(self.warnings)} warning(s) detected")
guest_smi = bool(self.status.get("guest_smi"))
guest_cuda = bool(self.status.get("guest_cuda"))
guest_cu_init = self.status.get("guest_cuInit")
container_cuda = self.status.get("container_cuda")
loader_layout_healthy = bool(self.status.get("libcuda_in_wsl_lib")) and bool(self.status.get("has_driver_loader_topology"))
if guest_smi and not guest_cuda:
if guest_cu_init == 2 and loader_layout_healthy and not self.status.get("smi_cuda_version_err"):
print(
textwrap.indent(
"High-confidence clue: cuInit returned CUDA_ERROR_OUT_OF_MEMORY even though "
"nvidia-smi and the WSL loader topology look healthy. In GPU-PV guests, that "
"usually points away from the basic /usr/lib/wsl copy step and toward host-side "
"partition sizing/MMIO limits or a kernel-module compatibility issue.",
" ",
)
)
print(
textwrap.indent(
"From an elevated PowerShell on the host, inspect Get-VMGpuPartitionAdapter -VMName <vm> "
"and Get-VMHostPartitionableGpu. If the adapter is using tiny/default Min/Max/Optimal "
"budgets, set explicit VRAM/Encode/Decode/Compute partition values with "
"Set-VMGpuPartitionAdapter and re-check HighMemoryMappedIoSpace.",
" ",
)
)
print(
textwrap.indent(
"If the host partition budgets already look sane, treat the next likely suspect as the "
"guest kernel/dxgkrnl combination itself (for example Ubuntu 26.04 on kernel 7.x with an "
"out-of-tree dxgkrnl copied from the WSL 6.18 branch).",
" ",
)
)
else:
print(
textwrap.indent(
"Likely issue: the guest can reach NVML/nvidia-smi, but the actual CUDA "
"user-mode stack is mismatched or incomplete. Re-copy /usr/lib/wsl from a "
"single current Windows driver snapshot and re-check loader precedence.",
" ",
)
)
if guest_smi and not guest_cuda and self.status.get("libcuda_in_wsl_lib") is False:
print(
textwrap.indent(
"High-confidence clue: libcuda.so* is missing from /usr/lib/wsl/lib, so the probe is using "
"/usr/lib/wsl/drivers/libcuda.so instead. In official WSL layouts, the CUDA shim normally "
"comes from /usr/lib/wsl/lib.",
" ",
)
)
if guest_smi and not guest_cuda and self.status.get("has_driver_loader_topology") is False:
print(
textwrap.indent(
"High-confidence clue: the WSL/NVIDIA loader topology still looks incomplete. The small libcuda shim may be present, "
"but the nested driver loader libraries (for example libcuda_loader.so, libnvidia-ml_loader.so, libnvdxgdmal.so.1, "
"libnvwgf2umx.so in an INF-style subdirectory) do not appear to be laid out the way the shim expects.",
" ",
)
)
if guest_smi and not guest_cuda and self.status.get("smi_cuda_version_err"):
print(
textwrap.indent(
"Additional clue: nvidia-smi reports 'CUDA Version: ERR!', which lines up with a broken compute "
"stack rather than a simple /dev/dxg visibility problem.",
" ",
)
)
if guest_cuda and container_cuda is False:
print(
textwrap.indent(
"Likely issue: guest CUDA works, but the container is shadowing the copied "
"WSL libraries or otherwise changing loader behavior.",
" ",
)
)
def exit_code(self) -> int:
if self.status.get("guest_cuda") is False:
return 1
if self.docker and self.status.get("container_cuda") is False:
return 2
return 0
def parse_args() -> argparse.Namespace:
parser = argparse.ArgumentParser(
description="Diagnose guest/container CUDA initialization for Hyper-V GPU-PV Linux guests."
)
parser.add_argument(
"--docker",
action="store_true",
help="Also test CUDA initialization inside a container (read-only).",
)
parser.add_argument(
"--image",
default=DEFAULT_IMAGE,
help=f"Container image to use with --docker (default: {DEFAULT_IMAGE}).",
)
return parser.parse_args()
def main() -> int:
args = parse_args()
runner = DiagnosticRunner(docker=args.docker, image=args.image)
runner.check_platform()
runner.check_dxg()
runner.check_wsl_payload()
runner.check_nvidia_smi()
runner.check_guest_cuda()
runner.check_container_cuda()
runner.print_summary()
return runner.exit_code()
if __name__ == "__main__":
raise SystemExit(main())
Run the script via python3 diag.py. If the output returns Result: 0 and correctly counts your GPU, your hypervisor bridge is flawless and ready for production.
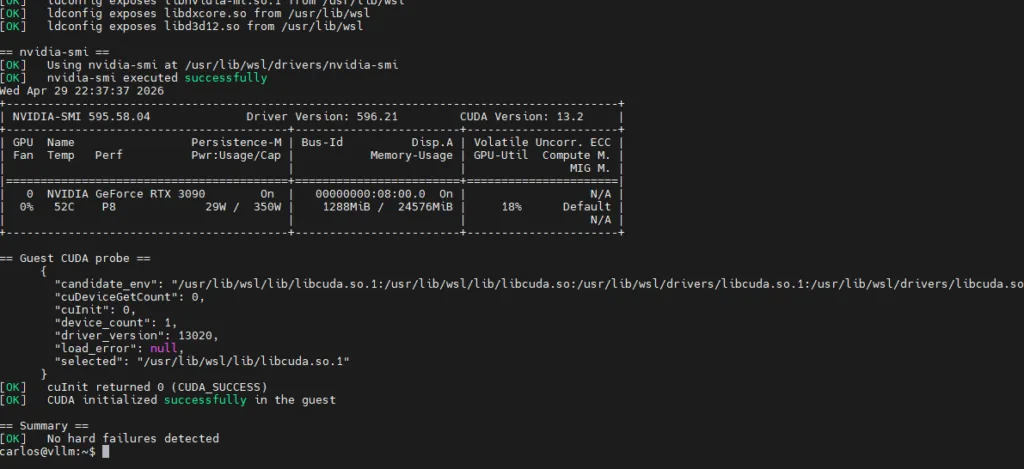
Docker & The Container Toolkit
In addition to the drivers, you must install the Docker engine.
sudo apt update && sudo apt install -y docker.io docker-compose-v2 curlBecause the standard NVIDIA Container Toolkit relies on detecting the word “Microsoft” or “WSL” in the kernel name (which our vanilla Ubuntu kernel lacks), it will fail to auto-inject the GPU. Instead, we bypass the toolkit entirely and pass the devices and library paths directly into Docker.
Test the bridge via direct passthrough:
sudo docker run --rm --device /dev/dxg -v /usr/lib/wsl:/usr/lib/wsl -v /usr/bin/nvidia-smi:/usr/bin/nvidia-smi -e LD_LIBRARY_PATH=/usr/lib/wsl/lib:/usr/lib/wsl/drivers ubuntu nvidia-smi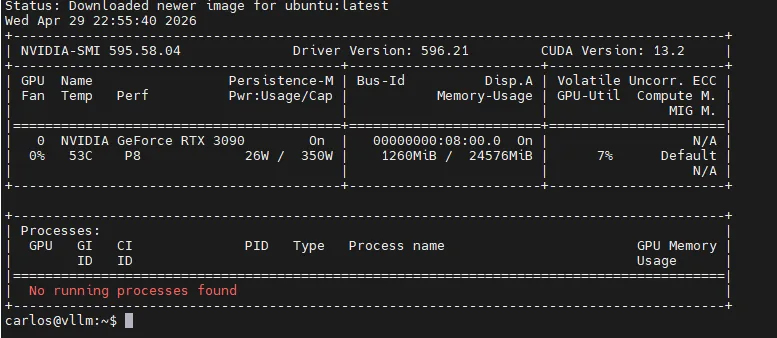
In conclusion, you now have a fully working Hyper-V GPU-PV Docker environment! Reach out if you run into any issues!